系统性能
查看机器配置
CPU配置
物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l # 2个
CPU核心数
cat /proc/cpuinfo| grep "cpu cores"| uniq # 10核心
逻辑CPU个数
cat /proc/cpuinfo| grep "processor"| wc -l # 40总核数 = 物理CPU个数 X 每颗物理CPU的核数 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
内存配置
查看内存总量
cat /proc/meminfo #32G监控命令
top
常用指令
# 显示进程运行信息列表。按下P,进程按照cpu使用率排序
top -c
# 根据PID查出消耗cpu最高的线程号(3034),显示一个进程的线程运行信息列表。按下P,进程按照cpu使用率排序
top -Hp 3033
# 将最耗费性能的线程号转为16进制(因为我们的java线程栈里面是使用十六进制显示的)(3034->0xbda)
# 执行jstack -l 3033 > ./3033.stack
# cat 3033.stack |grep 'bda' -C 8 查看问题代码proc
Linux系统上的/proc目录是一种文件系统,即proc文件系统。与其它常见的文件系统不同的是,/proc是一种伪文件系统(也即虚拟文件系统),存储的是当前内核运行状态的一系列特殊文件,用户可以通过这些文件查看有关系统硬件及当前正在运行进程的信息,甚至可以通过更改其中某些文件来改变内核的运行状态。
# 查看网络流量
cat /proc/net/dev
### 查看系统平均负载
cat /proc/loadavg
### 查看CPU的利用率
cat /proc/stat
等。。free
用来显示系统内存状态,包括系统物理内存、虚拟内存(swap 交换分区)、共享内存和系统缓存的使用情况,其输出和 top 命令的内存部分非常相似。
free [选项]
#free -hdf
Linux df(英文全拼:disk free) 命令用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计。
df [选项]... [FILE]...
# df监控工具
iostat
默认情况下它显示了与vmstat相同的CPU使用信息。
通常只对I/O统计感兴趣,下述命令只展示扩展的设备统计:
# 参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;1 10表示,数据显示每隔1秒刷新一次,共显示10次
iostat -d -k 1 10
# 使用-x参数我们可以获得更多统计信息,-c 参数获取CPU部分的值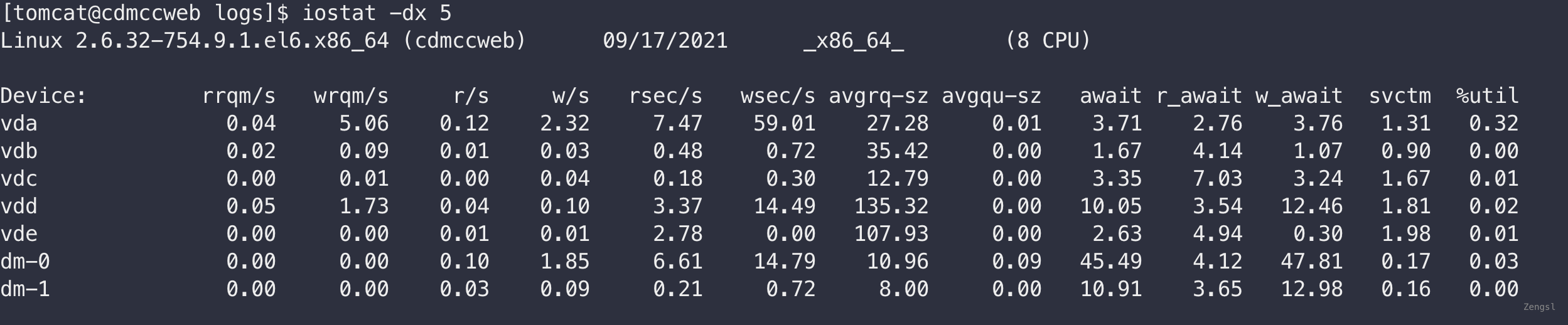
与vmstat一样,第一行报告显示的是自系统启动以来的平均值,每个设备显示一行。
- rrqm/s和wrqm/s
每秒合并的读和写请求。“合并的”意味着操作系统从队列中拿出多个逻辑请求合并为一个请求到实际磁盘。
- r/s和w/s
每秒发送到设备到读和写请求
- rsec/s和wsec/s
每秒读和写读扇区数。有些系统也输出为rkB/s和wkB/s,意为每秒读写的千字节数。
- avgrq-sz
请求的扇区数。
- avgqu-sz
在设备列中等待的请求数。
- await
磁盘排队上花费的毫秒数。很不幸,iostat没有独立统计读和写的请求,它们实际上不应该被仪器平均。当你诊断性能案例时这通常很重要。
- svctm
服务请求花费的毫秒数,不包括排队时间。
- %util
至少有一个活跃请求所占时间的百分比。如果熟悉队列理论中利用率的标准定义,那么这个命名很莫名其妙。它其实不是设备的利用率。超过一块硬盘的设备(例如RAID控制器)比一块硬盘的设备可以支持更高的并发,但是util从来不会超过100%,除非在计算时有四舍五入的错误。因此,这个指标无法真实反映设备的利用率,实际上跟文档说的相反,除非只有一块物理磁盘的特殊例子。
- CPU密集型的机器
vmstat输出通常在us列会有一个很高的值,报告列花费在非内核代码上的CPU时钟;也可能在sy列有很高的值,表示系统CPU吕用率,超过20%就足以令人不安了。在大部分情况下,也会有进程队列排队时间(在r列报告的)。
上下文切换(cs列),除非每秒超过100 000次或者更多,一般都不用担心上下文切换。 可以结合iostat查看磁盘利用率。
- I/O密集型的机器
在I/O密集型工作负载下,CPU花费大量时间在等待I/O请求完成。 通过vmstat会显示很多处理器在非中断休眠(b列)状态,并且在wa这一列的值很高
通过iostat输出显示磁盘一直很忙,%util的值可能因为四舍五入的错误超过100%
vmstat
vmstat命令,是 Virtual Meomory Statistics(虚拟内存统计)的缩写,可用来监控 CPU 使用、进程状态、内存使用、虚拟内存使用、硬盘输入/输出状态等信息。此命令的基本格式有如下 2 种:
vmstat [-a] [刷新延时 刷新次数]
vmstat [选项]
# 每5秒打印一次结果
vmstat 5
第一行报告显示的是自系统启动以来的平均值
- procs
r列显示了多少进程正在等待CPU,b列显示多少进程正在不可中断休眠(通常意味着它们在等待I/O,例如磁盘、网络、用户输入,等等)
- memory
swpd列显示多少块被换出到列磁盘(页交换)。剩下的三个列显示了多少块是空闲的(未被使用)、多少块正在被用作缓冲,以及多少正在被用作操作系统的缓存。
- swap
这些列显示页面交换活动:每秒有多少块正在被换入(从磁盘)和换出(到磁盘)。
它们比监控swpd列更重要。大部分时间我们喜欢看到si和so列是0,并且我们很明确不希望看到每秒超过10个块。突发性的高峰一样很糟糕。
- io
这些列显示有多少块从设备读取(bi)和写出(bo)。这通常反应列磁盘I/O。
- system
这些列显示列每秒中断(in)和上下文切换(cs)数量
- cpu
这些列显示所有的CPU时间花费在各类操作的百分比,包括执行用户代码(非内核)、执行系统代码(内核)、空闲,以及等待I/O。如果正在使用虚拟化,则第五个列可能是st,显示了从虚拟机中“偷走”的百分比。这关系到那些虚拟机想运行但是系统管理程序转而运行其他的对象的时间。如果虚拟机不希望运行任何对象,但是系统管理程序运行了其他对象,这不算被偷走的CPU时间。
提示
内存、交换区,以及I/O统计是块数而不是字节。在GNU/Linux,块大小通常是1024字节。
ifstat
ifstat命令 就像iostat/vmstat描述其它的系统状况一样,是一个统计网络接口活动状态的工具。ifstat工具系统中并不默认安装,需要自己下载源码包,重新编译安装,使用过程相对比较简单。
其他工具
iotop、iftop、htop
https://www.cnblogs.com/jins-note/p/9667342.html
性能测试工具
Lmbench3
Lmbench是一套简易,可移植的,符合ANSI/C标准为UNIX/POSIX而制定的微型测评工具。一般来说,它衡量两个关键特征:反应时间和带宽。Lmbench旨在使系统开发者深入了解关键操作的基础成本。
LMbench的主要功能:
带宽测评工具:读取缓存文件、拷贝内存、读内存、写内存、管道、TCP
反应时间测评工具:上下文切换、网络(连接的建立,管道,TCP,UDP和RPC hot potato)、文件系统的建立和删除、进程创建、信号处理、上层的系统调用、内存读入反应时间
其他:处理器时钟比率计算